Databases
Deploy the core database controllers included in the Panfactum framework.
PostgreSQL
The most popular relational database in the world is PostgreSQL. Many companies are able to rely on PostgresSQL to power their applications indefinitely. In addition to being extremely reliable, performant, and scalable, it can be easily extended to tackle many popular use cases such as full text search, AI vector database storage, geospatial lookups, etc.
We use it in the stack to power some more advanced foundational components such as the identity provider (following sections).
Deploy CloudNativePG Operator
While there are many ways to deploy PostgreSQL on Kubernetes, we prefer CloudNativePG which is a best-in-class Kubernetes Operator for managing the entire lifecycle of the PostgreSQL clusters in production-hardened manner.
We provide a module to deploy the operator: kube_cloudnative_pg.
Let’s deploy it now:
Create a new directory adjacent to your
aws_eksmodule calledkube_cloudnative_pg.Add a
terragrunt.hclto that directory that looks like this:14 collapsed linesinclude "panfactum" {path = find_in_parent_folders("panfactum.hcl")expose = true}terraform {source = include.panfactum.locals.pf_stack_source}dependency "linkerd" {config_path = "../kube_linkerd"skip_outputs = true}inputs = {}Run
pf-tf-initto enable the required providers.Run
terragrunt apply.
Note that this will only deploy the CRDs and operator. To deploy actual PostgreSQL clusters, you must create Cluster resources. We provide a module kube_pg_cluster that you can use in your projects to do this.
Test PostgreSQL Cluster
This section will deploy and tear down a test PostgreSQL cluster. While we recommend completing these steps to gain familiarity in working with databases, you can skip this without impacting your cluster’s functionality.
Deploy Test Cluster
To demonstrate the capabilities of PostgreSQL running in the Panfactum stack, we have created a demo module called test_kube_pg_cluster which is a thin wrapper around kube_pg_cluster.
Let’s deploy it now:
Create a new directory adjacent to your
kube_cloudnative_pgmodule calledtest_kube_pg_cluster.Add a
terragrunt.hclto that directory that looks like this:14 collapsed linesinclude "panfactum" {path = find_in_parent_folders("panfactum.hcl")expose = true}terraform {source = include.panfactum.locals.pf_stack_source}dependency "cnpg" {config_path = "../kube_cloudnative_pg"skip_outputs = true}inputs = {}Run
pf-tf-initto enable the required providers.Run
terragrunt apply.In k9s, notice that there is a new Cluster resource that will go through multiple statuses as it launches (
:cluster):
Switch to the pods view (
:pods) and notice several new pods will come up after approximately 2-3 minutes:
Notice:
This deployment is highly available with multiple postgres servers running (one writable primary, and a configurable number of read replicas). Terminating one of the pods will automatically execute a failover. Downtime to the writable master will only be a second or two.
“Pooler” pods are launched. These are PgBouncer instance. You should establish database connections to these services rather than directly to the databases to improve performance and resiliency.
Navigate to the S3 view in the AWS web console. Notice that a new bucket was created for the cluster:
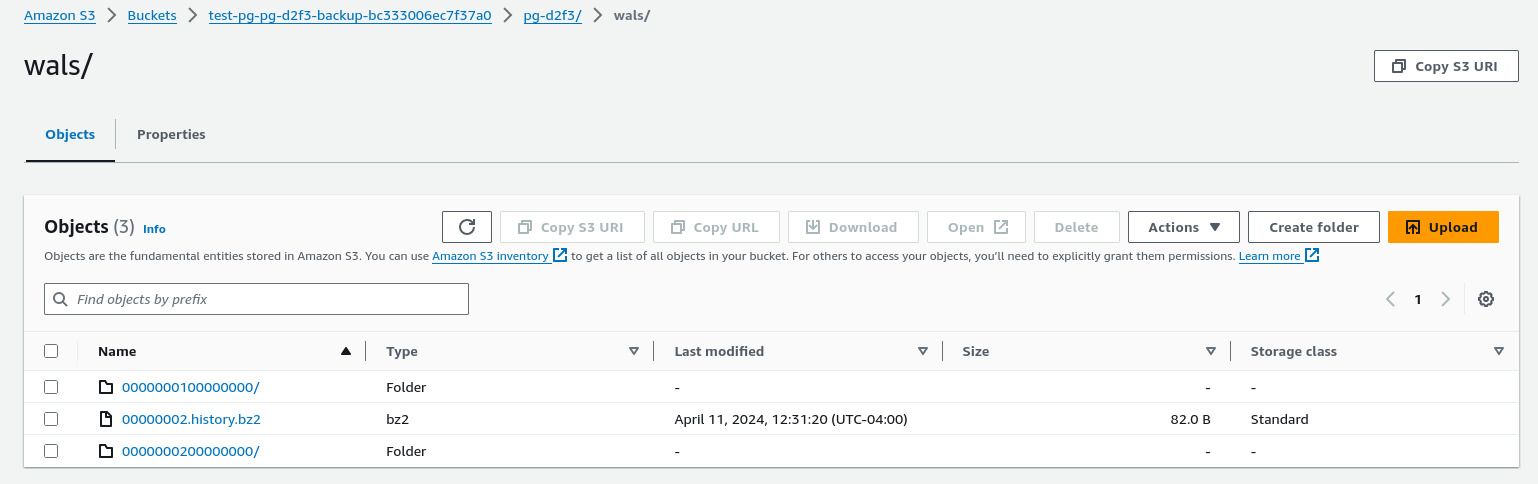
The cluster comes with a component that will automatically replicate the PostgreSQL Write-Ahead Log (WAL) to S3. This means that you have the ability to rollback the database arbitrary points in time. This is significantly more powerful than the hourly EBS snapshots deployed in the last section (although those will continue to be made as well).
While we won’t cover it in this guide, you would initiate backups using barman.
Connect to Test Cluster
We provide a handy utility to connecting to database clusters deployed via the Panfactum stack: pf-db-tunnel.
Let’s try it out:
Switch your Kubernetes context to the cluster you just deployed the database into by running
kubectx.Run
pf-db-tunnel --local-port 5432and complete the prompts.You should eventually receive an output like the following:
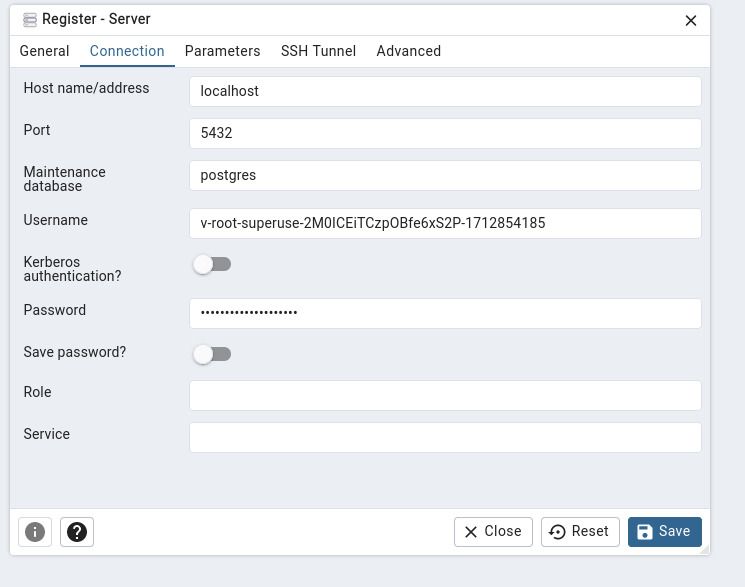
Terminal window Connecting to Vault in production-primary...Retrieved Vault token.Searching for all databases in production-primary...Retrieving Superuser credentials for pg-d2f3.test-pg from Vault at https://vault.production.panfactum.com...Credentials will expire in 8h or until tunnel termination:Username: v-root-superuse-2M0ICEiTCzpOBfe6xS2P-1712854185Password: rIoHh2O-eAc7GcRJDf66Running a tunnel on localhost:5432 to PostgreSQL database pg-d2f3.test-pg via pg-d2f3-pooler-rw.test-pg:5432!This command uses
pf-tunnelunder the hood so the connection is traversing through the SSH bastion deployed in inbound networking section.Note that the
kube_pg_clusteralso set up authentication with Vault and now provisions you dynamic credentials. These credentials will automatically be revoked as soon as you close the tunnel.In a separate terminal, launch
pgadmin4(can be installed withnix-shell -p pgadmin4-desktopmodeif needed). Once it is running, visithttp://localhost:5050/.Register a new server:
Set the connection details using the information displayed when you opened the tunnel:
You should now see the main pgAdmin4 dashboard and can begin running commands against the database:
Clean Up Test Database
Once you are done working with the test database:
Close the tunnel by running
^Cin the terminalRun
terragrunt destroyin thetest_kube_pg_clusterfolderYou will get an error like this:
Error: deleting S3 Bucket. This is because we protect the S3 bucket containing the database backups from accidental deletion. Delete this bucket manually via the web console.Run
terragrunt destroyagain.Remove the folder.
Other Databases
The PostgreSQL engine is the only one needed to complete the bootstrapping guide. As a result, we will delay installing additional databases until you need them.
However, the Panfactum stack comes with built-in support for many other database engines. We believe our stack contains the necessary databases to address the majority of use-cases an organization may face:
Relational: PostgreSQL (kube_pg_cluster)
Key-value: Redis (kube_redis_sentinel)
Message Broker: NATS Jetstream (kube_nats)
Ledger: Kafka (Coming soon)
Warehouse: ClickHouse (Coming soon)
We are focusing our investments on these core database modules to provide a best-in-class experience.
Additionally, you can easily add other custom database modules to the Kubernetes clusters in the Panfactum stack. Utilities like EBS snapshotting and autoscaling will automatically work. In the future, we will provide guides for how to extend the core Panfactum utilities such as pf-db-tunnel to include your custom database deployments.